Scaling up for an IoT World
May 01, 2017 - San Francisco, CAWith Fineo’s Beta availability (link), I thought it would be interesting to look at how Fineo actually supports IoT-scale ingest and eliminates the need for traditional pipelines and the maintainence of several data stores. The transfer and conversion of data between these data stores (known as an Extract-Transform-Load, or ETL, process) tend to be very manual and fragile, making them a constant pain point. By eliminating the core ETL processes, instead driving it into the core of the platform Fineo frees people from the burden of data cleanliness and management, allowing them to focus on their business.
The advent of the Interet of Things (IoT) means almost every industry is generating several orders of magnitude more data than they have ever seen. ‘Traditional’ web companies are the only place to come close to this scale of data. Unfortunately, the standard Big Data tools tend to be unwieldy and capital intensive (even though they run on “commodity” hardware). While many companies recognize the potential of Big Data, few can actualize it due to the difficulty finding experts to manage these distributed systems for many industries (i.e. its hard to convince engineers that counting bolts is interesting).
Fineo is a SaaS Big Data platform designed from the ground up for the brave, connected world in which we now find ourselves. Beyond completely elastic scalability with enterprise grade tooling, we are also looking to change how people manage their data with our No ETL tools.
Access
You can write in two modes: streaming or batch each of which has a similar, though independent, pricing model. This makes is very simple to scale - everything just works as you get more devices and data.
All reads - analytics, ad-hoc queries, daily operations - are handled by a standard JDBC driver (ODBC coming soon!). That means you can just plug it into your favorite analytics tools and everything just works. Or, if you are in the homebrew camp, you can easily roll your queries with standard SQL.
(No) ETL & Late-Binding Schema
Traditional ETL is widely considered a painful, thankless process that is necessary to achieving business objectives by providing low latency access to data, deep analytics and ad-hoc data science. Fineo’s No ETL tools make it easier than ever to iterate and manage a heterogeneous device environment. You no longer need to worry about simple things like renaming database columns (and managing the transformation of data from legacy devices) or completely changing a columns type (e.g. Celsius vs. Fahrenheit data when changing device components).
What would be a full time job for several engineers completely disappears in the Fineo framework, while simultaneously replacing the need for multiple data stores with a single, unified API.
In the future, we want to automate the entire ETL process. That means your Data Scientists can focus on insights, not being Data Janitors. This would be things like type clustering via Machine Learning, so new devices/events are instantly accessible and intelligible, so you can focus on using that data.
Behind the (Ingest) Curtain
Originally, the Fineo platform was built on entirely open source components enabling public or private cloud deployment. Our Beta will only be available on AWS - talk to us if you are interested in other/private cloud deployments - and to help move more quickly we carefully selected SaaS based replacements for some of the services. This allows us to run a nearly completely “NoOps” platform and focus on providing the truly innovative Fineo components.
Leveraging AWS
We leverage a host of AWS services for a couple of reasons:
- as we scale up, cost scales with us
- operational burdens are nearly zero.
Without further ado, here is the entire streaming ingest pipeline [2].
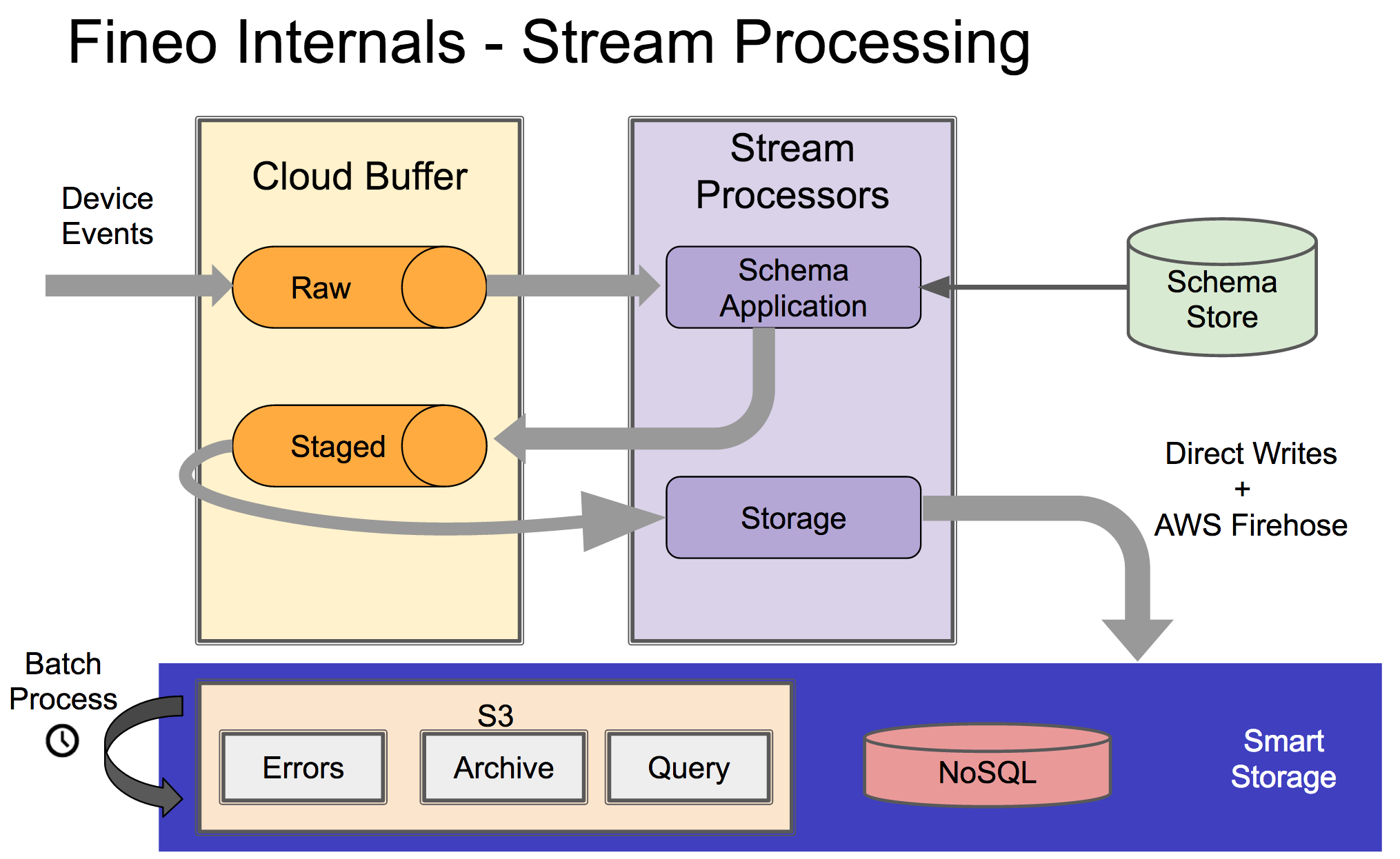
Basically, its a light stream processing layer over a standard lamdba architeture. Pretty simple, right? There are some subtle elements of this architecture that give us some pretty fantastic abilities when building for ‘enterprise grade’ infrastructure.
Outside In
One the edge sits the AWS API Gateway. Its a powerful tool that lets us easily define APIs and then interact with backend AWS services or our own API endpoints. Additionally, it also provides very strong, fine grained authentication and authorization services, making it a great basis for the user-visible side of things.
From there, we process the events in a series of ‘stages’ backed by Kinesis streams (essentially large, distributed, durable queues). We archive the results of each stage for backups and subsequently build multiple representations of the data for fast queries.
Making One Size Fit All
One single database/system rarely supports all the use cases; low latency is almost always at odds with high throughput. This is exactly why we leverage multiple data representations, so we can pick the right one for the query and mash up multiple sources for a optimal representation of the data under query.
The common ‘web’ case mostly cares about the most recent data, the events occurred in the last day or week, and fairly small volume: on the order of a millions of events. For this case, we leverage DynamoDB as our ‘nearline’ data store. It provides fast access to row-level data and scales dynamically with customer data needs.
We also have a secondary representation that is well suited to supporting Data Scientists and general analytics: a shredded columnar format (via Parquet) combined with the cutting edge read capabilities in Apache Drill and Spark to make deep, adhoc analytics blazingly fast. When leveraged with our No ETL tools Data Scientists can now more quickly and easily then ever investigate their data to derive insights that help drive deep understanding and decision making.
What’s really exciting is that from the outside, it all just looks like SQL! But instead of querying across a minute, you can query across a day, month or year and get blazingly fast answers.
The Stream Processing Pipeline
Kinesis acts as a core buffer for managing each stage of the stream processing pipeline. Each stage is implemented as an AWS Lambda function. The first stage processes the raw events into an Avro schema that we understand or kicks it out to an error stream. The valid records are then sent onto two places: the raw archive and the ‘Staged’ Kinesis stream.
These schemazited records are then processed by the ‘Staging’ Lamba function. Similar to above, we Firehose the incoming events (the schematized records) and error records to S3. The actual “work” of the stage is writing to Dynamo DB, so we can serve near-line queries. At this point, you could query the data through our standard JDBC driver.The archived stream is also the data source for our batch transformations that enable fast-restore backups and our deep analytics tools.
Batch Transformations
The S3 “staged archive” location is processed periodically with an EMR Spark cluster to do a few things:
- deduplicate records
- extract schema changes
- format records for read
- build a fast-restore backup
The key part of this job is transform events that have a known schema into a highly optimized, columnar format which enables the blazingly fast speed for ad-hoc analytics. We also process the columns without schema so we can still read them in an unoptimized, ‘flat’ JSON format, but lack some of the speed optimization of known data types. If we don’t recognize some of the data types, we will notify you so you can integrate it into schema or fix the error.
Since all the data is present in DynamoDB already, we can be a bit lazy about doing the batch transformations - taking days or weeks. This gives us a lot of flexibility around things like cost optimization, retries and extensive testing.
Pipelines Replayability Wins
Since each stage is stored in a new Kinesis stream (e.g Kafka topic) we have extensive replay abilities. Each Kinesis shard comes with 1MB/sec ingest and 2MB/sec reads. This gives us the ability to dark launch a completely parallel set of resources (lambdas, s3 files, etc.) at every stage, giving us deep confidence when rolling out a new release.
As mentioned above, we also leverage Firehose at each stage. On one hand, we get backups of each stage with the exact data. This allows us to recover from downstream processing errors (i.e. raw -> schema transformation has a bug) or act as several sets of backups. On the other, we now also have a complete record of events that we can use as another level of testing for new code. Rather than relying on Kinesis, we can replay the events directly ensuring that we can exactly mirror customer workloads in testing (hugely valuable for a enterprise environment).
Each stage can also see two main types of error - ingest/customer errors from bad data and commit/processing errors. For each error type we write them to a different Firehose stream. This lets us then tie in AWS notifications to alert when we get an error (as an S3 file). This can either be a notification directly to the customer - e.g. bad data - or waking up the Ops team in the middle of the night. Because the errors are archived into S3, we also can allow users to use Drill to query the errors with SQL.
OSS or SaaS
In the above architecture, you could replace Kinesis with Kafka, S3 with HDFS, Firehose with a number of open source batch engines, Lambda with Storm (or Flink or Samza), and DynamoDB with an open source NoSQL database (e.g Cassandra, HBase, etc.). Beside a few quirks, a heap of operational overhead, and the non-trivial overhead of running the servers for a small startup its a straightforward switch. We have the added advantage of being able to easily calculate the exact costs per tenant and can pass the costs directly onto users (so we never need to worry about running a cost-deficit).
However, as experts in distributed systems with a pedigree in Open Source, we can quickly shift to a completely OSS stack to either run in private clouds or to help drive down costs later 1. In fact, most of this will not be new for many folks at web companies. However, its often difficult to manage all these services and combining them all into a cohesive whole is certainly not trivial.
Wrap Up
As a SaaS provider Fineo gives you all these great things you would want with a flexible ingest pipelines, fast, IoT-centric storage and enterprise grade tools, without all the overhead of actually running it yourself.
Fineo really shines in three places:
- SQL everywhere
- Universal, low latency queries
- Dynamic schema at scale
The first two are pretty cool. Being able to use SQL everywhere means quick adoption across the company and natural, powerful query semantics. This power is accessible both through the web application, a JDBC driver or programatically through our web API.
Our cutting edge dynamic schema support brings the flexibility of NoSQL into a manageable framework with coherent schema changes and evolution. It helps customers move quickly without breaking things and quickly recover from mistakes, without losing information.
Really good ideas never seem to be uniquely developed - also true of quite a few bad ones - and such seems to be the case here. Our ingest pipeline looks a heck of a lot like Netflix and our DynamoDB schema looks similar to a common IoT style use case. However,we have some twists that make Fineo eminently attractive: SQL access, enterprise security and availability, low latency query and dynamic schema.
Want to learn more about the Fineo architecture? Check out the next post in the series: implementing dynamic schema.
Notes
1-costs
With economies of scale it can be much cheaper to run your own services, rather than leveraging SaaS. You are paying a premium for someone else to deal with managing the service - keeping it up, running quickly, etc - so you can focus on your business. In fact, this is the same logic for why you want want to use Fineo in the first place; we handle all the glue and management so you can focus on using the data.
2-batch
The batch mode is very similar, but also supports ingest via S3 files or larger batches (up to 10MB right now) of events. Its preferable if you are cost sensitive (it can be 10x or more cheaper) and can tolerate some lag between ingest and being able to read the data. Be on the lookout for a follow up post on how we manage the batch process!
-----------
Like this sort of stuff? Consider subscribing to the RSS feed.
blog comments powered by Disqus