Translating SQL queries for schema on NoSQL
May 05, 2017 - San Francisco, CAFineo uses a novel semi-schemaful approach to unlock the potential of NoSQL data stores, while simultaneously enabling ‘metalytics’ queries by providing an engine that seamlessly supports everything from nearline, operational queries (e.g. low latency, small scale) to deep, ad-hoc analytics. Primarily powered by Apache Drill and a complex set of query plan steps, we can find the optimal representation of the data to answer a query and push down work to edge, making answers fast.
Drill’s planning engine is built on Apache Calcite - a generic SQL planner and in-memory execution engine. Fineo adds a custom ‘storage adapter’ that translates queries into a series of transformations, that eventually generates a limited number of plans; the plans vary in the underlying storage they query. For instance, one plan could query all the DynamoDB tables, while another queries one DynamoDB table and a number of S3 directories.
Because we are focusing on the time-series domain, we just need to find the best way to get the data for the user’s query over a given time range. Each storage engine provides information about the ‘hardness’ of the query, which is surfaced into the query planner and the leveraged to find the lowest ‘cost’ plan - the one that answers the user’s query as fast as possible.
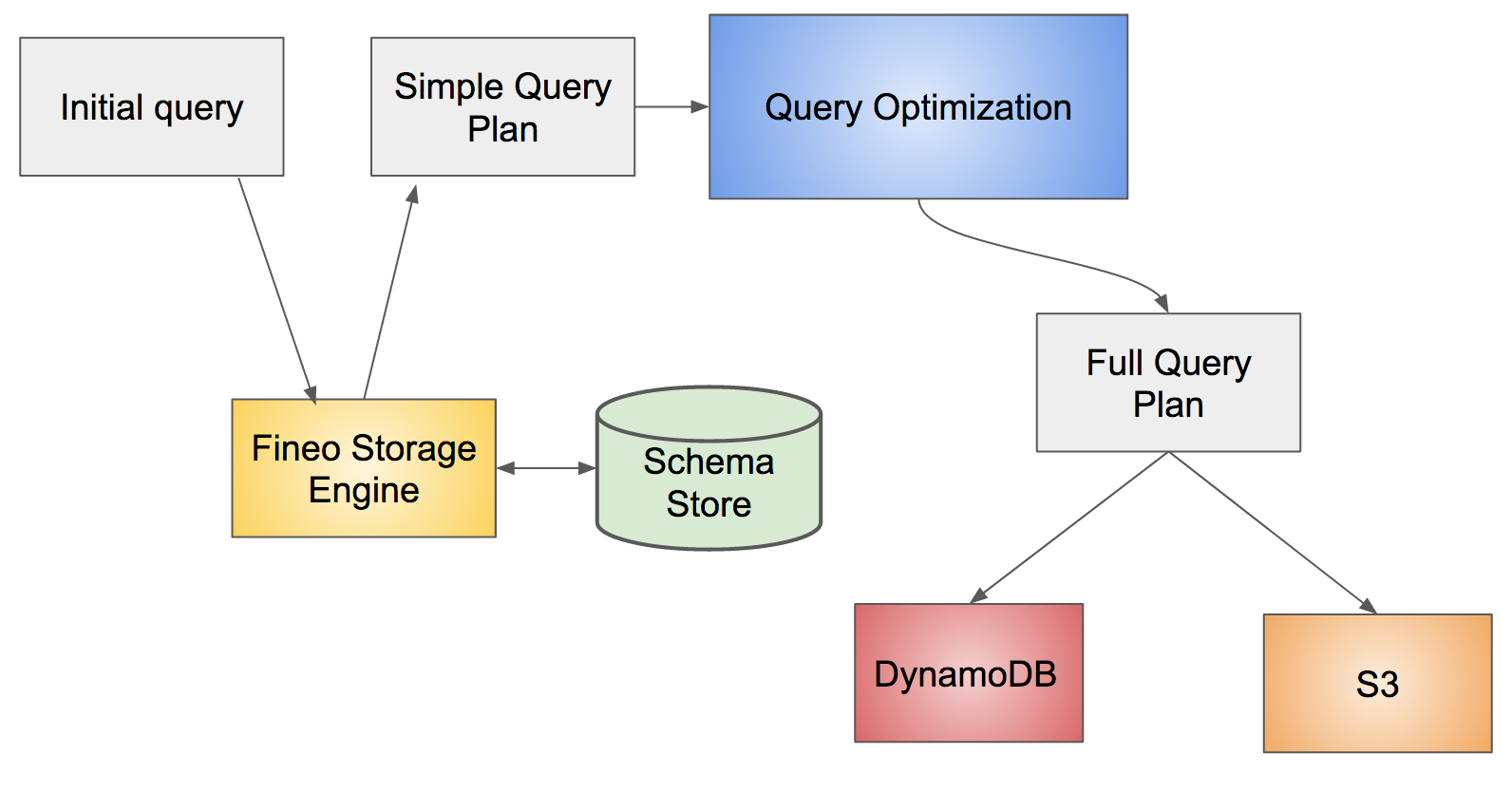
We force the query optimization process into a set of stages with a set of custom ‘marker’ relations that can only be handled by the Fineo rules, helping ensure the process remains understandable. Each stage handles some aspect of the query generation, be it translating the user’s schema into queries for underlying storage or finding the right storage components to support the specified time range.
![]()
Stage 1: Managing Schema
The execution of each query starts with a request to the schema store for the available schemas for the tenant. We can thus match up the user’s expected fields to the query fields, translating the query into something more extensive in the underlying store to encapsulate all the fields. The schema also gets passed the down to the edge operators so it can understand the fields that are coming back from the raw storage.
A user query can start as:
> SELECT temp from MY_TABLE
and then get translated at the database interface layer to something like (we also enforce the tenant id for all results)
> SELECT temp, temperature, tmp FROM FINEO_TABLE WHERE tenant_id = 'some-tenant-id'
But really, we start with a query plan for the Fineo table that looks like:
LogicalSort
LogicalFilter
LogicalProject
FineoRecombinatorMarkerRel
LogicalTableScan
LogicalTableScan
The FineoRecombinatorMarkerRel acts as the first gate of translation and the two logical table scans are for the potential read of DynamoDB and S3. This marker will also eventually get translated into a physical “Recombinator” with the job of recombining the underlying data fields into a coherent, user-facing representation.
Stage 2: Translating Table Types
The next stage translates the logical table types to actual queries on the underlying engine reads. Here, we inject tenant, metric and time range filters based on the query. We also expand the original query fields into the full range of potential field names.
LogicalSort
LogicalProject
FineoRecombinatorMarkerRel
LogicalFilter
LogicalTableScan
DynamoRowFieldExpanderRel
LogicalTableScan
We also can inject casts for known fields to the correct type from the underlying store. If the fields are already the known type, the cast has not performance penalty, but eases the translation of fields that previously did not have a type (and thus stored as a string).
Stage 3: Logical Planning
Now we actually get into translating logical table scans into a scan of the DynamoDB table(s) and/or the S3 files. Standard Drill rules also attempt to prune the directories or tables to read, based on the timestamp/time-range requested by the user by ‘pushing down’ these filters into the respective scans.
The Fineo rules also generate a set of plans to query an overlapping range of data between DyanmoDB and S3, from which the lowest cost plans survives to the next stage. DynamoDB tables cover weekly chunks of data and are removed after a few months; S3 partitions down to the day granularity, but covers all history. We lazily update the S3 storage (the data is already available in DynamoDB), allowing us to merely consult a water-mark for the latest S3 translation and generate potential query plans from there.
For instance, consider that we have the following DynamoDB tables:
2017-04-16_2017-04-22
2017-04-23_2017-04-29
2017-04-30_2017-05-06
and a watermark at 2017-05-02 (May 2nd, 2017). For a query that does not include a timestamp, we could then generate plans like (intermediate steps removed):
## Plan 1
FineoRecominator
DynamoTableScan(2017-04-16_2017-04-22)
DynamoTableScan(2017-04-23_2017-04-29)
DynamoTableScan(2017-04-30_2017-05-06)
FineoRecombinator
ParquetScan(s3://data.fneo.io/stream/parquet/tenant_id/2017-01-01,..., s3://data.fineo.io/stream/parquet/tenant_id/2017-04-15)
## Plan 2
FineoRecominator
DynamoTableScan(2017-04-23_2017-04-29)
DynamoTableScan(2017-04-30_2017-05-06)
FineoRecombinator
ParquetScan(s3://data.fneo.io/stream/parquet/tenant_id/2017-01-01,..., s3://data.fineo.io/stream/parquet/tenant_id/2017-04-22)
## Plan 3
FineoRecominator
DynamoTableScan(2017-04-30_2017-05-06)
FineoRecombinator
ParquetScan(s3://data.fneo.io/stream/parquet/tenant_id/2017-01-01,..., s3://data.fineo.io/stream/parquet/tenant_id/2017-04-29)
## Plan 4
FineoRecominator
DynamoTableScan(2017-04-30_2017-05-06)
FineoRecombinator
ParquetScan(s3://data.fneo.io/stream/parquet/tenant_id/2017-01-01,..., s3://data.fineo.io/stream/parquet/tenant_id/2017-04-29)
## Plan 5
FineoRecominator
DynamoTableScan(2017-04-30_2017-05-06)
FineoRecombinator
ParquetScan(s3://data.fneo.io/stream/parquet/tenant_id/2017-01-01,..., s3://data.fineo.io/stream/parquet/tenant_id/2017-05-02)
Each plan uses progressively more of the underlying S3 storage fields, rather than the DynamoDB tables, up to the water-mark.
Similarly, for a bounded time range we could prune more of the parquet scan down or even eliminate it. Additionally, we can also push down the time-range into the DynamoDB request, generating very specific query timeranges for the tenant, further limiting the amount of data that is read.
In this stage we also have some ‘push down’ rules that allow any user projections (e.g. SELECT field1 ... would become Projection relation on field) or filters to pass through our Recombinator and into the underlying scan, again helping to limit the amount of data necessary to fulfill the user’s request.
All of this translation is managed by a custom rule that executes against an injected ‘rel’ that can only be removed by the rule; there is only one valid path to process the query plan to the next ‘stage’ and it has to go through each custom rule.
We rely on Drill to select the lowest cost plan, based on the expected cost of each plan in CPU, memory, and network use.
Stage 4: Physical Planning & Execution
Finally, the logical plan is converted into a physical execution plan; this plan can be pushdown down the Drill worker nodes and executed in a tree. Drill is very good about minimizing the time to a result by generating optimized code for each query and ubiquitously leveraging zero-copy buffers.
The main work for Fineo is the in the FineoRecombinator. When we execute the plan we turn the dynamic column results for each underlying table into a coherent set of columns for the user, based on the schema we loaded at the start of the query planning. For instance, dynamo might return a row with the values:
| Column | Value |
|---|---|
| temp | null |
| temperature | 24 |
| tmp | null |
| timestamp | 149377839700 |
| tenantid_metricid | tid_mid |
and we auto-magically translate it to:
| Column | Value |
|---|---|
| temperature | 24 |
| timestamp | 149377839700 |
| tenant_id | tid |
| metric_id | mid |
based on selecting the first non-null value for the user-visible columns. We ensure that all rows have a tenant id, metric id and timestamp, but rely on an ‘upstream’ filter to match the tenant and metric id, as well as filtering out any errant rows outside the requested time range.
Summary
Fineo provides an novel layer of schema flexibility that helps users unlock the power of NoSQL data stores - the flexibility and speed of development. Free to change the data model or absorb mistakes, users can focus on deriving value from that data, rather than trying to clean it and put it into the right place. Simultaneously, Fineo also enables an unheard of range of queries in a single API because we can dynamically select the optimal representation and push down multiple components to make queries return blazingly fast.
Want to learn more about the [Fineo] architecture? Check out the next post in the series: multi-tenant SQL security in-depth.
-----------
Like this sort of stuff? Consider subscribing to the RSS feed.
blog comments powered by Disqus