Multi-tenant SQL Security In-Depth
May 08, 2017 - San Francisco, CAMulti-tenancy is an abstraction for a big, hard group of problems that touches on security, scalability, resource consumption and quality of service. Generally attempting to back-fit multi-tenancy is, at best, hacky and less than satisfying; at worst, its a recipe for disaster.
With Fineo, we designed for multi-tenancy from the start. Part of that comes from my background at Salesforce, where multi-tenancy was baked into everything we did. The other part comes from our SaaS business model and the desire to scale users super-linearly to costs (so profit increases with the number of users).
My biggest concern was making sure that user data was completely inaccessible to other tenants, while remaining co-located. Concurrently, access had to be fast on a per-user basis. Finally, I also wanted to ensure that we could easily fork a single tenant environment or migrate a group of users with zero downtime.
Confused Deputy Problem
Ensuring that a user is authenticated on the ‘hard shell’ of a system is a relatively easy problem handled in standard web architectures with things like LDAP or one of many user authentication tools. However, it is crucial to ensure these credentials, or some form of them, are passed through a multi-tenant application to ensure that sub-layers cannot inadvertently allow a user access (through bugs or malicious use) to unapproved data. This is known as the confused deputy problem, or as wikipedia puts it:
The unintentional release of data can occur maliciously or accidentally through a bug, but I wanted to ensure that at every level user data was segregated and required information from the level above to provide access, avoiding any leakage.
In all its dirty glory, here’s the entire read architecture, with our security broken out into layer.
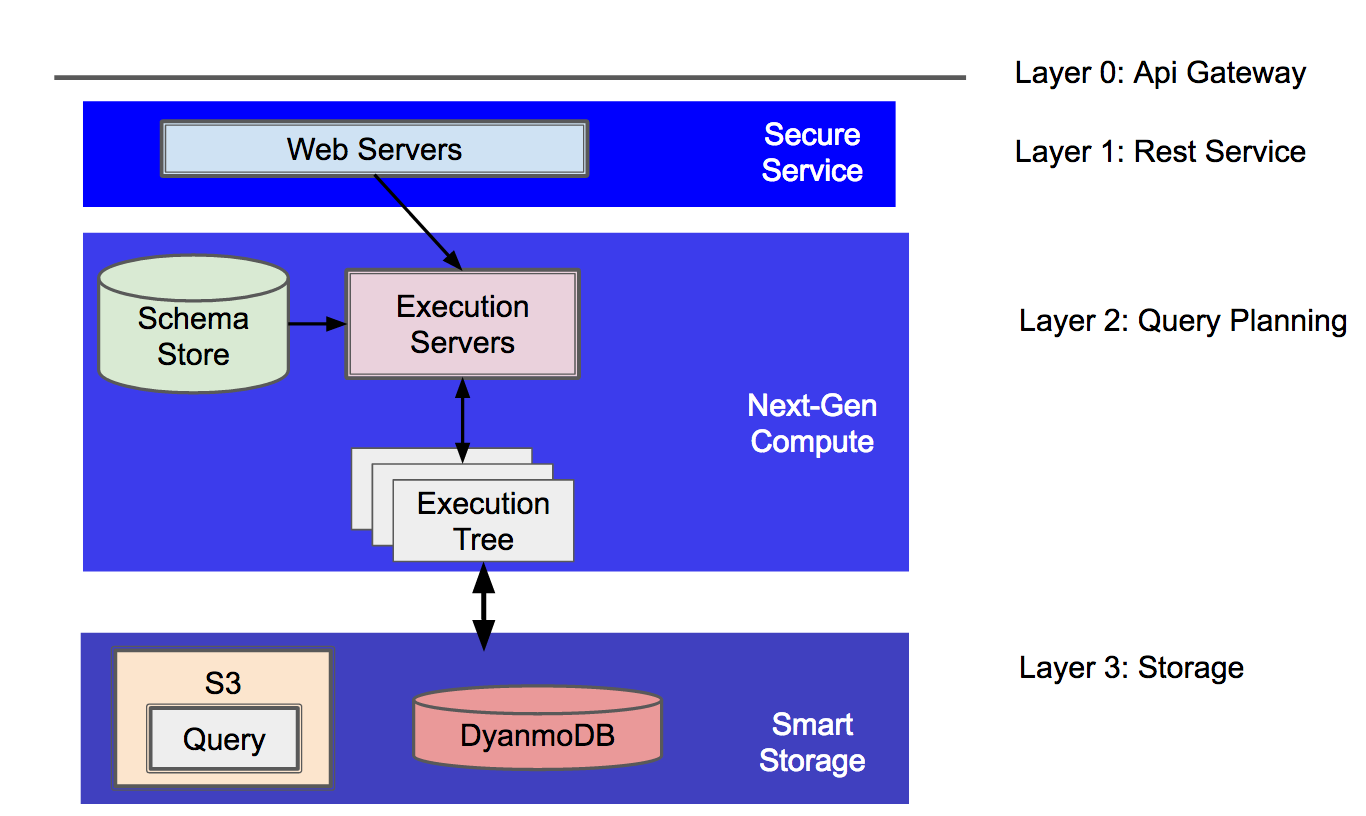
Let’s step through the precautions at each layer.
Layer 0: API Gateway
At the very edge, Fineo uses the AWS API Gateway to handle all of our authentication and simple access control. Each device has an access/secret key pair used to sign requests, while users credential (username/password) are managed via AWS Cognito.
Our simple ‘hard shell’. Yes, hard shell’s are known to not be viable in the cloud, but it does enforce a minimum effort to attack. Each layer below is also controlled with AWS IAM controls to ensure only the specific services can make requests.
This outer layer ensures that we don’t have unauthorized access. We plan to move to an internal authentication service as a cost saving measure, but for now, AWS provides a quick and easy way to get going fast.
Layer 1: REST Service
All SQL read requests are passed from the API Gateway and sent to a simple REST server. The REST server is glorified proxy for the underlying distribution query planning and execution engine.
The REST server also ensures that all requests must come tagged with an API Key for the user (this is baked into our JDBC client driver as well).
After extracting the API Key we take a preliminary pass at parsing the SQL request (via Apache Calcite). From there, we inject a WHERE clause into the request, enforcing that the API Key from the request matches the Tenant Key in the data. This ensures that users cannot access other users data, at a query level.
Layer 2: Query Planning/Execution
The query planning and execution layer takes the SQL request and breaks it down into its component parts, determines the optimal way to execute the query and then distributes the work to a group of workers that each process a chunk of the data, before passing it up the execution tree and eventually to our proxy server, and finally back to the user.
Fineo’s core execution engine is Apache Drill, but with a somewhat invasive ‘FineoTable’ layer that translates a user query into an execution across several different data stores. In the query plan generation, our custom query rules ensure that there is an API Key filter in the query (inserted from Layer 1) before the query can complete the planning phase (see the translating SQL blog post for more).
Additionally, all table metadata is translated from the multi-tenant schema store and only returned on a per-tenant basis. This ensures that other tenants cannot even accidentally see the tables for another tenant.
Layer 3: Data Storage
Fineo transparently leverages two different data storage layers to enable both low-latency, row-oriented queries (what happened in the last 5 seconds?) as well as deep, cross cutting analytics and ad-hoc data science (what’s the average number of users with at least 10 interactions in the last 5 years?). The disparity in type of query also predicates a disparity in the type of storage, if you want to ensure fast answers.
We use Amazon DynamoDB, with a tenant and timestamp oriented schema, to handle the low-latency queries. Analytic style queries are handled via Apache Parquet columnar-formatted files, stored in S3.
Our goal was to build the simplest system we could, that supported a broad range of use cases.
3a: DynamoDB
Choose to use DynamoDB because it was a fully-managed data store (saving huge operations overhead), wildly scalable, row oriented and supported a good amount of operator pushdown.
As a time-series oriented service, we still had to do a bunch of work around aging off older data (time-range tables) and managing data recency with write-time tables (see Using DynamoDB for Time Series Data for more info).
The trick then is figuring out the correct schema to ensure that tenant are separated, access is fast and not impacted by other tenants. The schema we came up with was not ground breaking:
| Hash Key | Range Key |
|---|---|
| Api Key , Logical Table Id | Timestamp |
To access any data, you must provide the tenant API Key and the logical table id (from our schema service, itself organized per-tenant) before being able to read a row.
This schema also ensures that access to different logical tables for the user (i.e. one for each of their products, like ‘temperature senors’ or ‘vacuums’) is fast, since user/table data is:
- being co-located
- ordered by timestamp (our ‘primary’ key - it’s a timeseries platform).
The chances of two tenants accessing the same dynamo instance are very slight and even less of a concern given a stable auto-capacity monitoring and management layer (running out of read capacity? automatically turn up the server capacity!).
3b: Amazon S3
Fineo optimizes for access to recent data by leveraging a row store. However, we also wanted to support analytics, data science, and ad-hoc queries; queries that can span huge swathes of the data and tend to be more columnar based. We turned to to using Apache Parquet sorted in Amazon S3, grouped by tenant and date. This gave us a folder hierarchy like:
/tenant api key
/year
/month
/day
/hour
Which allows our query execution easily avoid data for other tenants (remember the API KEY filter injection?), but also prune down the potential directories to search to a very specific range. Using Parquet’s columnar formats allows us to quickly and easily answer roll-up style queries.
S3 storage is also notably cheaper than running an online database and provides us even more flexibility in speed of storage by enabling Glacier support.
We could have added in another layer of protection using tenant-specific access control and encryption, but given that DynamoDB doesn’t support server-side encryption, it didn’t seem worth the effort (and there was no pressing user need for it!).
Per Tenant Deployment
A single tenant deployment can be necessary when the tenant has specific requirements around security (e.g. custom keys) or data commingling, among many other potential reasons. We built this into the architecture from the start and ensure that every single pre-production test run also executes against a single-tenant architecture (exact same calls, different backend), even if we didn’t have that requirement yet. It also helped when developing a sandbox for local testing: we could stand up the whole infrastructure, just like production.
The core separation for a single tenant came in the REST layer (Layer 1). Here, the tenant’s API Key was required to match one and only one API Key (rather than just matching the one assigned to that user) bound to the server’s deployment. If the API doesn’t match, then the request is rejected. Otherwise, we use the same separation described above in query execution and data storage, but on physically separate resources.
Zero Downtime Migration
Tenants might need to be migrated to other servers if they tend to have a dramatically different workload than other customers or group of customers to help balance access, as well as diversifying risk.
Leaving data in place
When a tenant is being migrated, but is happy to remain in the same AWS Availability Zone, we can just spin up a new instance of the query execution engine and point the dynamo access to the old tables and the new per-tenant prefix. Then, as the data from the old tables naturally ages off, we eventually will only be accessing the new, tenant specific tables.
Note that S3 doesn’t actually need to be ‘migrated’ because it is already tenant separated and provides no control over location.
Physical Migration
If we need to move a tenant to another location, for instance because they want even lower latency access, it’s a similar activity to a standard migration. We start with a bulk copy of the S3 data to the new region. All new writes get sent to the new tables, while reads will be done from both the old and new tables. However, because these are geographically distributed, this is notably painful solution - AWS egress data costs hurt and latency will be generally very bad.
However, we can backfill the ‘new’ tables from the S3 files that overlap the time-range that is not aged off. At the same time, we can do copies of the current table in the background to ‘catch up’ any data that has not been converted to long term-storage. This enables us to minimize the window of ‘slowness’ for the user during the migration.
At the end, asynchronously turn off the access to the ‘old’ table and return to a fast, single-location access for the migrated tenant, all with zero-downtime.
Wrap Up
When designing for multi-tenancy, its best to build it in from the beginning. It’s easy to setup per-tenant instances/infrastructure, but tends to lose when considering the bottom line. Instead, you need to carefully consider how to logically separate data while preserving a high quality of service, eventual migration and preventing unauthorized access - even unintentionally.
Want to learn more about the Fineo architecture? Check out the next post in the series: Using DynamoDB for Time Series Data.
-----------
Like this sort of stuff? Consider subscribing to the RSS feed.
blog comments powered by Disqus