Building Up Fineo's Continuous Integration with Jenkins
May 22, 2017 - San Francisco, CAGetting a robust continuous-integration (CI) suite was an early priority at Fineo. By spending some upfront time getting good infrastructure in place we could move dramatically faster down the road; with a distributed, micro/nano-service based architecture, in-depth testing across the stack is a must.
In the beginning, we started out with just a bunch of unit and simple integration tests kicked off by Jenkins. We added in a suite of local end-to-end tests using resources as close to production as we could get. However, running in AWS means there isn’t always a good (or availabile) analog for services, so you have to test in the cloud.
We devised a basic set of ‘customer-like’ use cases and leveraged AWS Cloudformation templates replicate a production environment against which we could run the life-like tests. With this production-like suite we could confidently automatically deploy to production - there were no other tests to run that would give us more confidence.
Then we started to get fancy.
Debugging test runs was still a pain, involving manually parsing through kilobytes of logs and ugly messages delineating stages, like:
---- DEPLOY Started ---
** Stream Processing Deploy started **
...
... < lots of text >
...
** Stream Processing Deploy COMPLETED **
--- DEPLOY COMPLETE ---
We were also storing all the jobs as chains of scripts - Bash, Ruby and Python - which starts to get unwieldy very quickly.
Enter Jenkins Pipelines - a Groovy DSL for job definition and a good looking UI for tracking steps. Still a bit rough around the edges, but a huge step up from chaining bash scripts and reading reams of terminal output.
Quickly after discovering Pipelines, we started to slowly migrate jobs over to the Pipeline framework. Some of the jobs took tens of minutes to run - the perfect opportunity to work on the conversion of the long-running job.
Building to End-To-End Testing
The first stage in our build process is local unit and integration tests, for each component. Most of the infrastructure is Java based, and built by Maven, so this is as simple as mvn clean install. Often this will trigger downstream jobs to also build (they depend on the project at that changed). There are a couple of ‘sink’ jobs - jobs that don’t trigger a downstream job - that we monitor to kick off the local end-to-end testing.
The local end-to-end testing stands up local versions of all the AWS services we leverage - DynamoDB, mock Lamdba, Spark - and runs a set of tests that leverage the system in a ‘real world’ like cases as we can find, checking things like ingesting, reading, schema management and batch processing.
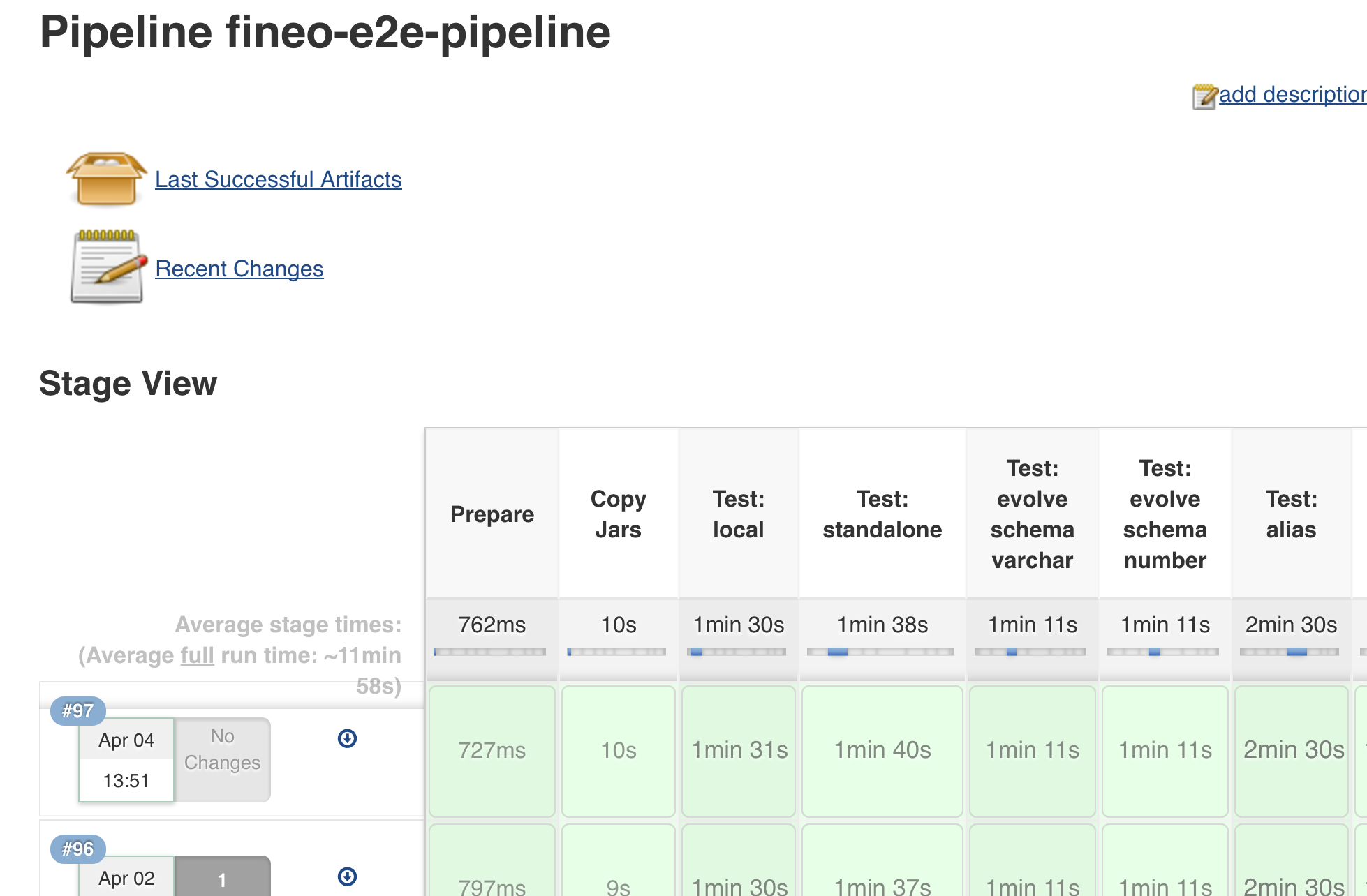
Each test is its own stage in the Jenkins Pipeline, allowing us to easily see progress in the test suite.
Testing in the Cloud
Supposing the end-to-end testing completes successfully, we then kick off the production-like testing pipeline against AWS. This has a two main phases: tenant-specific deployment and any-tenant deployment. The tenant specific validates that only a specific API Key can be used to access the data, while the non-specific merely ensures you have a valid API Key.
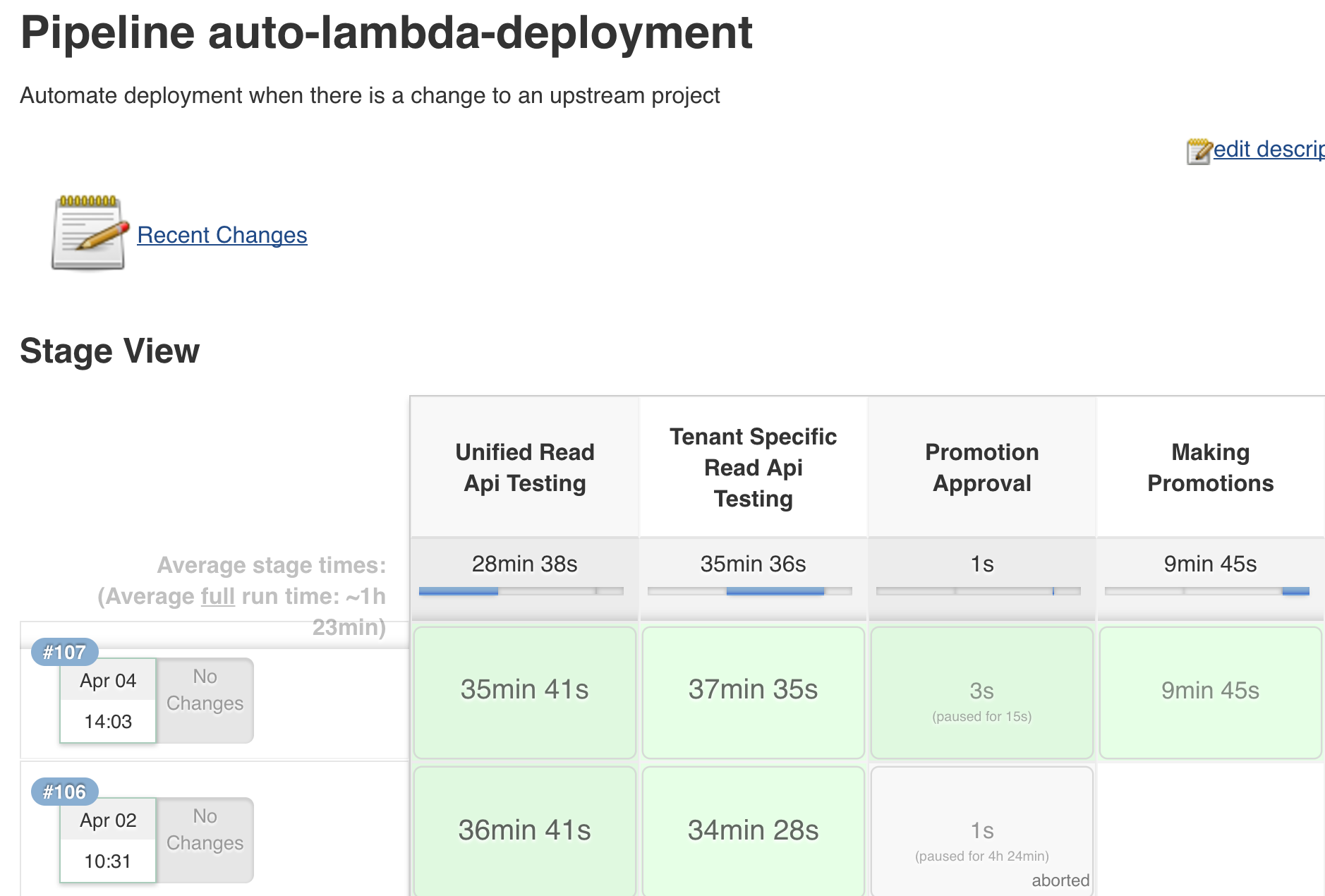
In both the tenant-specified and non-specific cases, we do a complete deployment of the software stack, just like in production. The only difference to production is the name of components and where they write data. A huge boon (and really the best/only way to do this on AWS) is AWS Cloudformation, which allows you to provide templates of your resources and semi-automatically upgrade them as the templates change.
At the end of the pipeline we request user input to verify the component(s) to deploy. This helps ensure we don’t have a lot of thrash in the infrastructure - code changes regularly. The input step is more a concern of too much automation, too early; as things no longer scale to manual automation we expect this step to be automated as well. In fact, as we mentioned above - there is no more surety we could have about the code because it captures the core user test cases.
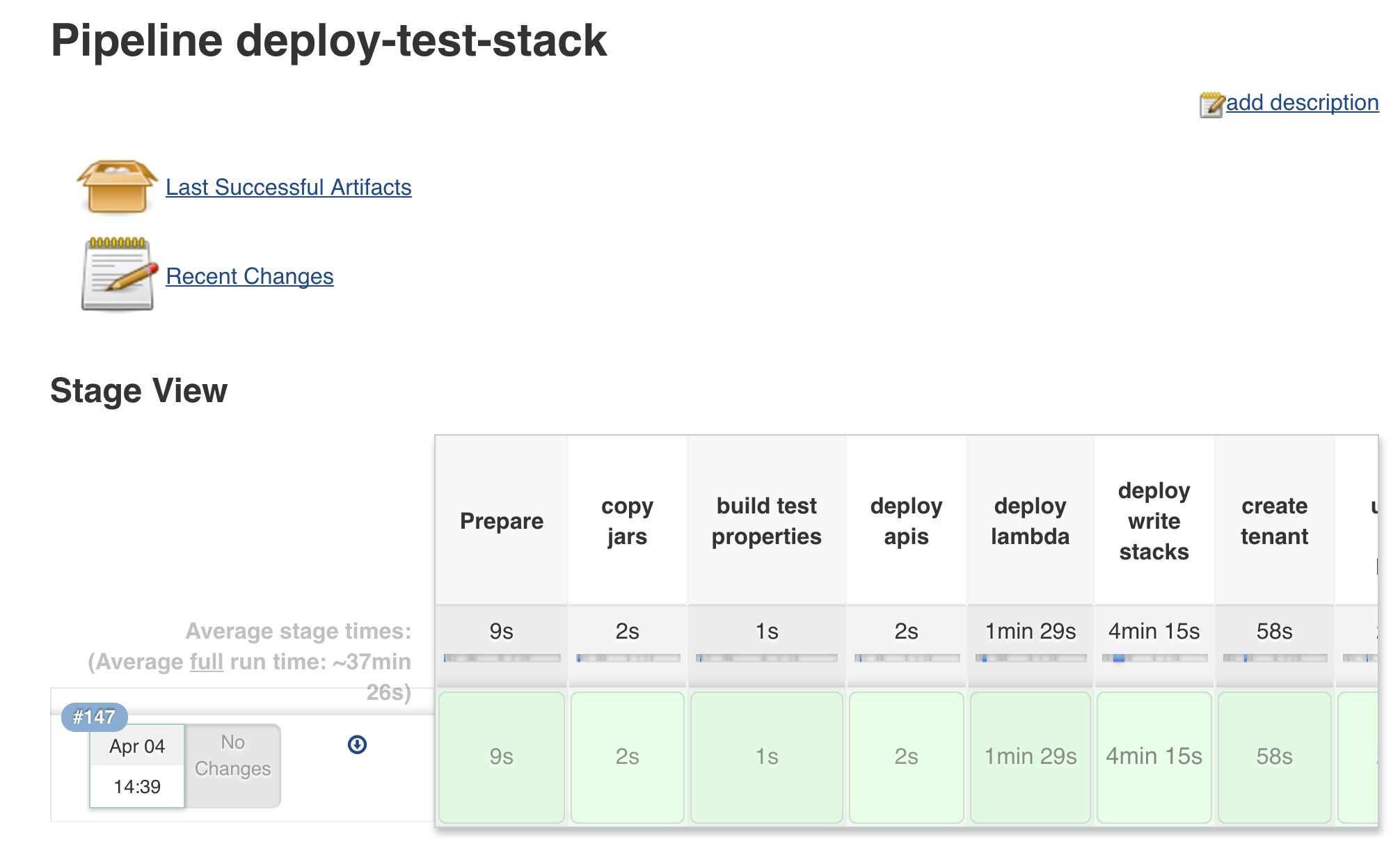
Cloudformation is great, as long as you stop trying to manually manage the Cloudformation instantiated resources (just don’t, it **will break things **). Templates ensure you get the same thing every time and don’t have snowflakes. Our templates are mostly composed of pointers to resources, so the first phase of the deployment requires pushing the resources into S3, then updating the templates and finally actually instantiating the Cloudformation “stack” (i.e. set of resources).
Templating the Templates
In generating a production-like test environment, we needed a way to reproduce production. We were already using Cloudformation to ensure we had declarative infrastructure that could be deployed onto any AWS Region quickly, so it was naturally to look at reusing the templates for testing. Since the Cloudformation template files are just text (JSON or YAML), we used a templating library to ‘template the [Cloudformation] template’ to generate both the test Cloudformation template(s) and the production templates.
Specifically, we used Liquid templating language, as most of the test infrastructure is also ruby. This ended up being a huge time saver as we could reuse a lot of common definitions (i.e. s3 bucket locations or API gateway monitoring options) and have a common way to define test infrastructure (e.g. all s3 test paths start with /test).
We could then easily combine a set of declarative template and property files, deployment specific variables, and test transformations into one cohesive whole that that was succinct and readable.
Here’s a snippet of one of our Liquid-Cloudformation Templates:

It was so useful we also used Liquid templating in generating the API Gateway definition files. It was invaluable for things like create a common response language/protocol across multiple apis (and you don’t just jam all the endpoints into a single api, right?).
Drinking Champagne
Using our generated templates, a full production-like deployment can then be stress tested across a variety of real-life use-cases. Since we are a time-series platform, and its important to drink your own champagne, we capture the amount of time it takes to perform each of the tests and feed that data back into our platform, as well as the CPU/Memory consumption of our Jenkins Server.
If the time/resources for any component is wildly different from the historical values (avg, 75%, 90%, 95%, 99% - you are monitoring percentiles, right?) we fail the test run, roll back the test infrastructure and alert the folks with code changed involved; performance is just as important as correctness for us.

Each AWS end-to-end deployment is a Jenkins Pipeline job, which is itself kicked off by the full End-to-End testing Pipeline job, while the end-to-end deployment cleanup is a traditional Jenkins ‘freestyle project’. Eventually, we plan to move over the cleanup job to a Pipeline job, but until then we can easily run a heterogeneous set of jobs without issue.
Summary
Jenkins Pipelines enable code-based definitions of jobs and can be incrementally added to existing installations. And they are way better that chained scripts, once you get used to the DSL. By leveraging Cloudformation and some “templating of templates”, you can create production-like deployments for comprehensive integration testing. With these tools, there is really no reason to not be setup an integrated, automated continuous integration tool that automatically promotes changes into production with high confidence.
Want to learn more about the Fineo architecture? Check out the next (and final) post in the series: Harder isn’t Valuable: Looking Back on Fineo
-----------
Like this sort of stuff? Consider subscribing to the RSS feed.
blog comments powered by Disqus