Scaling Out Fineo
May 12, 2017 - San Francisco, CAI had a couple of questions come up from the Fineo ingest post on how we make things scalable, what happens when throughput limits are hit, etc. that I thought would be interesting to explore. For a refresher, here is the high-level view of Fineo’s architecture:
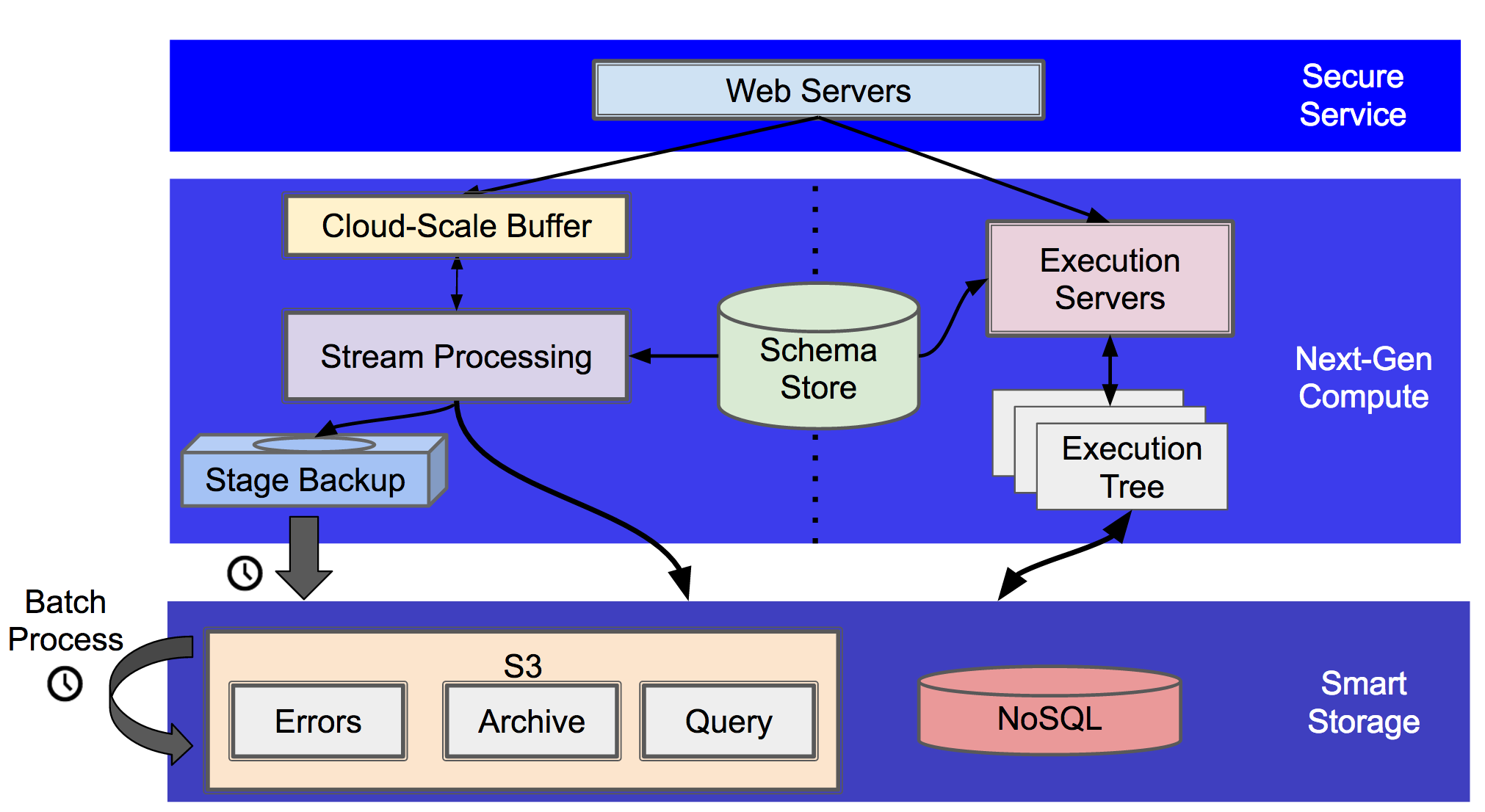
Scalable API
At the top layer, we leverage AWS API Gateway to manage the external REST endpoints and user/device authentication. Its transparently scalable and integrates well with IAM credentials (device auth) and AWS Cognito (user auth); it’s our ‘hard shell’. For a relatively low amount of requests (like those seen in a startup), API Gateway is very cost effective at $3.50 per million API calls received + data transfer costs, saving us the burden of writing, running and managing another service. Eventually, we will need to move off of API Gateway, both from a cost perspective and to get around its 30 second request/response timeouts.
Managing buffers
The core of the Fineo write architecture is a series of AWS Kinesis stream, aka a fully managed, 24hr data buffer. Each buffer shard has a write limit of 1MB/sec and read limit of 2MB/sec and costs $0.015/hr and $0.014 per 1M ‘put’ requests. Again, for a startup this is significantly cheaper and easier than trying to run Apache Kafka (the open source equivalent) on our own. The question is then, “what do we do when demand increases?”
The writes for each tenant are hashed into the Kinesis shards based on the tenant id and the timestamp, approximating a uniform distribution of the events across all the shards. Then, we just need to ensure that capacity stays ahead of the demand. Writes per Fineo user are limited to 200 events/sec, so as long as events stay below 5KB each, we can approximately allocate one Kinesis shard per tenant.
However, this misses a couple of things.
First, we support multi-put requests, making it relatively easy to go above 1KB/sec for many use cases. At the same time, many users aren’t aren’t always going to be using the full capacity, so by keeping 1 shard per user, we are wasting capacity (and money). Finally, we still need to ability to scale up the number of shards to support demand spikes.
Enter the AWS Kinesis Autoscaling Util. A tool and standalone service that manages the amount of shard capacity based on the monitored PUT and GET rates.
As long as we scale up when PUTs exceed a fixed percent (e.g. 50% of capacity), we can quickly respond to user demand shifts, while remaining cost effective. Its not 100% perfect as very fast demand bursts will overwhelm the system, but it captures more than 80% of our needs.
Stream Processing
All of our stream processing is handled via AWS Lambda. Again, it has the same properties of being auto-scalable and fully managed, while remaining cost effective at relatively small scales. It starts to make more sense to move off of Lambda as the number of events increases, instead moving those functions into a standalone EC2 instance that leverages the AWS Kinesis client library to access the streams.
Fast, easy, simple to test. Check!
Storage
We have two main storage engines - S3 and DynamoDB. Both are fully, managed, scalable, etc. etc. - all the things we are also looking for above.
Firehose Streams to S3
S3 is fed by AWS Firehose, which lets us buffer data for between 60 seconds and 900 seconds (15 minutes), and by default 2,000 transactions/second, 5,000 records/second, and 5 MB/second. This handles much of our early scale and can be scaled up either by opening an AWS case or managing a set of Firehoses and distributing the writes across them. We then periodically batch process the Firehosed records into a partitioned, columnar format for use with client reads.
Because the Firehose copies are done at every stage of the stream processing, we have between 4 and 6 copies of the data at all times, across the Firehoses themselves, S3 and DynamoDB. This makes it very unlikely to lose data and easy to recover because its already formated in the stream processing layout.
DynamoDB Storage
We spent a bit of time thinking about the DynamoDB schema to ensure that its going to be reasonably scalable and avoid ‘hot spots’ (see DynamoDB for time series post for more details). Assuming that we have relatively uniform writes and reads, the remaining overhead is then to just ensure that our DynamoDB shard allocation is appropriate to our workload.
We leverage time-range grouped tables to partition events, allowing us to quickly ‘age-off’ older data (by deleting tables) and economically adjust the allocated capacity for each table as needed. The key assumption here is that more recently written data is also the most frequently accessed data. Its easy to go overboard and do something like a table per day, but at a limit of 256 tables, we can quickly run out of tables for production and test environments. At the same time, too few tables means allocating extra capacity to data that is rarely accessed, effectively wasting money.
We settled on a table per week of event time range, so everything with a timestamp in week 1 goes into table 1, everything in week 2 goes into table 2, etc.
Now, just like with Kinesis, we need to be able to turn up and down the capacity of the cluster. There are a couple of tools to do this: dynamic DynamoDB, that runs a server, or one of many lambda implementations. I’m partial to lambda functions for ease of deployment, but really its up what fits your deployment model. The only kicker is that DynamoDB can only be scaled down four times a day, so you have to be a little judicious in allocating capacity. Since we rely on lambda functions and an idempotent write model, we can support retries and being a little bit slower to scale, saving us money but at the cost of a slightly higher latency for users.
Schema Storage
The backing for our schema store is DynamoDB, which allows us the same scale, flexibility and operations overhead (or lack thereof) as the core data. Currently, we just directly read the data from DynmoDB and rely on machine local caches to minimize lookups for older schema. This does create a bit of interdependence in the architecture in that we have to be careful when upgrade the schema tools to ensure we remain backwards compatible on the storage layer.
We will eventually move to a more fully managed, internal ‘schema service’. Nothing needs to change from the external schema user perspective, as we are just swapping out an implementation. The fully managed service lets us scale and cache more aggressively, but means there is another thing we need to manage, deploy, etc. that didn’t seem worth it with the small size of the team (relying instead on our high communication bandwidth the manage the coupling in the deployment/code).
Query Execution
We have two main components to query execution: a query server and an Apache Drill cluster. The query server runs as a simple AWS Elastic Beanstalk Java application. Because it is essentially stateless, we can transparently scale up and down the number of servers behind the load balancer based on user demand using standard AWS rules. Upcoming work includes adding client pinning to servers so we can support larger queries that take multiple round-trips.
Apache Drill similarly supports a dynamically scalable cluster. As resource demands grow, we can just add another node to the cluster to pick up the extra work. We trust to decent AWS network architecture to avoid major data locality issues (all the data is stored in DynamoDB and S3 anyways, so its not going to be truly local regardless). Similarly, as work drops below a given level, you can decommission nodes. This is more of a manual process, or driven by a custom watcher, and can be down via a separate monitoring server or in AWS Lambda, just like with Kinesis and DynamoDB.
Wrap Up
At Fineo we designed for scalability from the beginning, while still remaining cost effective. By thinking about not only how we are going to scale now, but also what that is going to cost and how to support the same (or better) scalability down the road at a lower cost, we can move at startup speed and cost. By separating out the architecture into different layers and ensuring that they are independently scalable ensured that we have no bottlenecks. Since we are a small shop, it was imperative that we cut down on operations work, so we could focus on building new features and growing the business. In leveraging full-managed services and auto-scalability monitors we not only freed up our time, but run a better service at a lower cost.
Want to learn more about the Fineo architecture? Check out the next post in the series: Supporting Schema Evolution and Addition.
-----------
Like this sort of stuff? Consider subscribing to the RSS feed.
blog comments powered by Disqus